Archive
Education Policy in the Election 4: Accountability, Intervention and School Turnaround
By: Simon Burgess
Schools are given two highly valuable resources: the potential of the nation’s children and a lot of public money. While £40bn sounds like a lot of money, it pales into insignificance compared to the value of improving human capital.
Schools should be accountable for how they deal with these: to parents for their kids’ progress and to the taxpayer via central government for their use of public money. In England, the accountability system has two components: performance information in the league tables and Ofsted reports. This accountability matters. We have shown that the publication of school league tables improves school performance, and have shown that the detail also matters. (It may just be election fever but there seems to be a danger of ad hoc extras being tacked on to this framework: the Tories for example “… will expect every pupil by the age of 11 to know their times tables off by heart, to perform long division and complex multiplication and to be able to read a novel. They should be able to write a short story with accurate punctuation, spelling and grammar.” This does not seem helpful).
School turnaround
The important policy issue now is about beefing up the link between the information provided by the accountability system and action to turn low-performing schools around. There are plenty of examples of individual schools experiencing a dramatic turnaround – see this example just this week. But the policy goal is to make this systematic rather than serendipitous. This is part of the rationale for a ‘middle layer’ of oversight in the education hierarchy, between schools and the Department of Education.
Why is this needed? We currently have two main channels for action.
The first is bottom-up, from parents choosing schools. Parents scrutinise the school league tables and decide which schools to apply to; low-performing schools get fewer applicants and so come under pressure to raise their game. This is the school choice channel for school turnaround. It works to a degree, but is not very strong (for reasons on another day) or very quick. The substantial attainment gap that opened up between England and Wales after the latter abolished school tables was due in part to that mechanism. We speculate that it was also due in part to schools’ reactions to the ‘shame’ felt by the low-performing schools in England that Welsh schools could hide from.
The second channel is a recent market-contestability measure: the potential setting up of a free school in response to low performance was meant to keep all schools on their toes. The evidence suggests there is little competitive spill-over pressure and it is not credible as a source of ongoing pressure.
There is a third potential channel that is resisted: Ofsted is resolutely determined not to do school intervention, but to stick to inspecting and reporting.
The ‘Middle Tier’
So the ‘middle layer’ is to make a stronger link from information to action. It is also proposed because of the craziness of having central government be directly responsible for over half the secondary schools in the country.
What should this be like? One option is for it to be left to academy chains to fulfil this role. While these groups are growing significantly, they nevertheless account for around half of academies and obviously no non-academies. Their regulation is an important issue for the next parliament.
So a comprehensive statutory body is better. The Coalition set up Regional Schools Commissioners to fulfil this role for academies. Their role is precisely to intervene to deal with poor performance, but is limited to academies and free schools: “Regional schools commissioners are responsible for … intervening in underperforming academies and free schools in their area.” They are required to monitor academy performance and take action when required. The Commissioners are supported by a small number of experienced local academy headteachers.
RSCs versus DSSs
The alternative is the proposal from Labour for Directors of School Standards (DSS). There are similarities but also a number of important differences. Similarities: the number one remit of a DSS is school turnaround: “facilitate intervention to drive up performance – including in coasting and ‘fragile’ schools”. The mechanisms for turnaround are pretty similar, though emphases and language differs. The DSS document emphasises a requirement to engage in “collaboration”. It’s possible that this may become something closer to academisation of a school including acquiring a sponsor in extreme circumstances. The Tories propose to dramatically increase the number of schools at risk of forced academisation.
The first and most important difference is that a DSS will cover all schools in her/his area. This will be achieved by essentially turning all schools into academies. This seems much more sensible, coherent and efficient to take all schools under a single umbrella. A second difference is that there will be many more DSSs than RSCs: there are 8 RSCs and suggestions of perhaps ten times that many DSSs. This is also an improvement – if taken seriously, this is a big job.
I think that the DSS proposal is very positive. The risk is that two factors will overwhelm the post-holders. First, they are responsible for more or less everything to do with schools: attainment obviously; but also financial probity (very specialist skills needed), and then also “British values”; obesity; personal, social and health education; and so on. Arguably, they should be asked to focus solely on attainment and school turnaround. Second, they are to have very little support. The DSS will have “a small back-up secretariat providing only the most essential administrative support”. Unless the DSS is just meant to sit in an office and issue edicts, this won’t work; more support will be needed.
Competitive donations
By: Sarah Smith
*The following blog by Sarah Smith is related to her recent publication – Competitive helping in online giving*
In next Sunday’s London marathon, the elite runners will battle it out for the men’s and women’s titles but another competition of sorts will already have taken place on charity runners’ fundraising pages. Each year, millions of pounds are raised in sponsorship donations, most through online fundraising pages which make it easier for fundraisers to raise money – and for charities to claim Gift Aid. But the fundraising pages also create a public platform for giving, with implications for how donors behave.
It will surprise few to learn that donors look to amounts given by other people in deciding how much to give. A large donation (£100+), particularly one made early on, can have a sizeable effect, increasing subsequent amounts given by an average of £10. More surprising, is that at least part of the effect of large donations is to elicit a competitive response by males in the presence of attractive female fundraisers. In biological terms, male donors appear to engage in “competitive helping”.
In a paper out today, we report the findings of a study of competitive helping based on fundraising pages from the 2014 London Marathon. We looked at the responses to large donations and compared how the responses varied by donor gender and fundraiser gender/attractiveness (do male donors increase their giving more in response to a large donation when there is an attractive female fundraiser?) and the gender of the person making the large donation (do male donors increase their giving more when the person making a large donation was another male?). Attractiveness was scored on the basis of external assessments of the fundraisers profile photos and attractive was defined as the top 25% of scores.
The results are striking. We confirm that large donations elicit a positive response among subsequent donors in terms of how much they give. But the increase in giving triggered by a large donation is FOUR TIMES GREATER among male donors responding to a large donation given by another male donor in the presence of an attractive female fundraiser. It is hard to think of another explanation for this, other than a biological mechanism – male donors compete, albeit possibly subconsciously, with other male donors for the attention of attractive females. By contrast, there is no such response among female donors.
What are the implications for fundraisers? Getting generous friends to donate early will help to raise more money. It is also important to choose a good profile picture – and one in which you are smiling. Not everyone can be among the most attractive fundraisers, but our results also show that a picture in which the fundraiser is smiling can be just as effective, boosting donations by more than 10%.
Education Policy in the Election 3: Autonomy, Regulation and Academy Chains
By: Simon Burgess
Over half of all secondary schools now have Academy status, and the number will continue to grow rapidly in the next parliament. The case for academy schools is largely the case for school autonomy, and there is robust evidence from US Charter schools that autonomy can be helpful in raising pupil attainment. While the constraints on schools might have been overstated after Local Management of Schools, there is really no going back, and schools will almost certainly retain most or all of their ‘freedoms’.
But there are some important issues about the governance and autonomy of academies at a different level. These have been hardly discussed at all and, given the sheer number of academies, may well become one of the most serious issues for the next Secretary of State to deal with.
Academy chains are now a big part of the education scene, reportedly covering about half of all academies. They have also come to bear the burden of quite a lot of policy hopes for school turnaround. But policy-makers need to think more about the governance by and of chains.
There is also a paradox here – if academies were born from a desire for autonomy, how much autonomy do the schools have within a chain? And if the most effective chains are the ones keeping the tightest grip on their schools, did we get wrong the level at which to increase autonomy? Should it perhaps be groups of schools that have autonomy (chains and of course, ironically, local authorities), rather than individual schools? While leading commentators champion autonomy, this is usually meant as autonomy from government rather than autonomy from Chain HQ.
There are three main issues: the formation of school chains or groups, the activity and performance of groups, and the setting up of new schools.
Formation of school groups
One of the most important things we want policy to achieve with school chains is to mimic the operation of a market, in the following sense: we want highly successful schools and leaders to provide education for more pupils and unsuccessful ones for fewer. The formation of school groups can help a lot to achieve this. We want existing high performing schools to form a group with (in slightly less polite language, take over) a nearby low-performing school. Or an existing chain of high-performing schools to do that.
There seems to be little point in encouraging just random assemblages of schools to join together beyond pooling back-office functions and bulk-buying stuff. More clearly, we would surely want to rule out a group of all local low-performing schools banding together. Why? Two reasons – first it removes effective choice from parents if all local schools are of the same ‘brand’. Secondly, by removing choice it also removes the pressure to improve. While all this seems ‘top-down’ in fact the idea is simply to mimic a well-functioning market in which the successful performers grow and either take-over or out-compete low-performers.
As the number of school take-overs and chains and ‘brands’ increases, there will be issues of market power to think about. This is a major issue in hospitals, but they are an order of magnitude bigger so not a major worry yet.
What do school groups do?
There is a tendency (until very recently, basically a blind hope) to see all chains as good things – highly effective or at worst, benign. Recent research, however, including from the path-breaking Chris Cook, suggests that perhaps just a couple of chains are transformative (ARK and Harris), and the others are pretty average; one chain, AET, has been strongly criticised by OFSTED. (You can now see for yourself the stats on the secondary school chains, having first read the health warnings about the data).
The widespread current view is that what school groups do is aid collaboration. Who could be against collaboration? Two points to make. First it is not clear that collaboration in the everyday sense is what effective school chains do. Some do no doubt. But in some cases it is more that the over-taking chain does some possibly rather un-collaborative turning around of the taken-over school. This is surely what policy makers and local parents want. That may not always work, but I think it is a mistake to see chains as synonymous with collaboration.
Second, the London Challenge is seen as the epitome of school collaboration, and the London effect is cited as evidence that this works. I have written about that here, here and here, so no more now; just to say that while the London Challenge may have done many wonderful things for London schools, there is little evidence that it has impacted dramatically on pupil attainment.
In summary, collaboration may not be what the few effective chains do, and there is little evidence that collaboration works to raise attainment.
Setting up new schools
The organisations in prime place to set up new schools should be existing high performing schools, or existing groups that have shown that they can deliver a high quality education. Whilst there should definitely be an open and transparent competition to set up new capacity, we could use a deliberately loaded question: is there any reason why this group should not provide a new school?
What about Free Schools? These are essentially academies but set up following proposals from groups other than the LAs. In principle the idea is to make the education market ‘contestable’ and to provide the competitive pressure to keep schools on their toes and performing well. However, the evidence does not suggest that this is having much impact.
The big issue associated with free schools is this: there is only limited capital to spend on setting up new schools. So there is a strategic choice to be made between provision of extra capacity in a place where schools are ineffective but places are plentiful, and neighbourhoods where there are insufficient places. And of course, where schools are ineffective, places are almost bound to be plentiful.
Two conclusions: contrary to Cameron’s announcement of an expanding free school programme, we should abandon the current policy of building free schools in the hope that they will raise standards all around. However, where new school places are needed, we should retain the principle that outsiders are able to propose to set up a new school as part of an open competition, but with a strong presumption in favour of existing high performing schools or chains.
Education Policy in the Election 2: School budgets
By: Simon Burgess
Does money matter for schools? Money matters for the provision of most things. And in one sense, obviously it does – people’s jobs are at risk with budget cuts, promotions are postponed and tight budgets just make life a lot harder for Headteachers and Governors.
And yet whether money matters for pupil attainment is much less clear. In fact, while there is evidence on both sides, possibly the majority of researchers in this field would agree that increases in a school’s resources are unlikely to have a major effect on attainment. This is in large part the debate about the number of teachers a school has relative to its pupils (class size) but it is also broader than that.
It’s not that we haven’t seen big increases in spending. Over the last ten years of the Labour government, 2000 – 2010, real per pupil spending rose by 68%. While GCSE scores have risen over that period, we have not seen anything like a commensurate rise in attainment. (Quite why money doesn’t appear to help much is a really interesting question, but not one for today). More broadly, one of the findings from the international comparison of attainment in PISA is that money does not buy success; one of the ‘seven big [education] myths’ set out by PISA is “it’s all about money”.
Nevertheless, the parties’ proposals for the education budget over the next parliament are interesting. Both Conservatives and Labour have made slightly differing pledges on ‘protecting’ the school budget. These have been decoded and quantified by Sam Freedman, one-man fact and analysis centre, now Research Director of TeachFirst. Labour promises a real terms protection of the entire 3-19 budget, but not a per-pupil protection, while the Conservatives promise a cash per-pupil protection of the schools budget. His best estimates are that under a Conservative government the implied cut for schools is about 10.5% and under a Labour administration a cut of about 9% because of steeply rising pupil numbers.
On top of inflation and rising pupil numbers, schools face higher costs from higher pension and national insurance payments, so budgets are definitely going to be squeezed.
Budget cuts?
What would be the likely consequences of any substantial budget cuts for schools? How would schools respond? The scientifically correct answer is “who knows”. Our analysis of schools’ financial decisions in the happier times of budget increases showed that there was zero consensus of action among schools on how to spend it.
This graph shows the distribution of schools’ spending by category depending on how much their income rose or fell between 2008/9 and 2009/10. The box plot shows that for each group of schools and in each expenditure category some schools made big increases and some made big cuts. For any group of organisations there will be differences in emphasis, but this shows wildly different decisions being made in similar circumstances. Fewer than half of schools made an increase in spending on teachers their largest change.

Of course, down is not the same as up, and some cuts could be severe; but it is very difficult to predict how schools will react to budget cuts, and even harder to predict the impact on pupil attainment.
The Pupil Premium
The big innovation in schools’ budgets over this parliament has been the Pupil Premium (PP) championed by the Liberal Democrats. It is paid to the school for each disadvantaged pupil in the school. While it is definitely an innovation, it is also important to recognise that the per-pupil funding for schools with many disadvantaged children was substantially higher than other schools under the previous government; see this for example. The PP started at £430 per pupil, increasing to £1300 for primary school pupils and £935 for secondary school pupils in 2014/15.
The PP has been set up very well, in all but possibly one aspect. It is directly attached to an individual pupil which does make it different to what came before. Schools can plan financially on the basis of their current stock of PP-eligible pupils, and the admission of new intakes has clear financial implications. The funding was guaranteed for a number of years and was easily predictable. Also, the fact that the rate per child started relatively low and then increased substantially was a smart move as schools were not faced with an immediate supply of resource that they did not know how to spend.
The negative aspect is the restrictions placed on how schools could spend the money. It’s clear why the restriction was made that the funds have to be spent solely on the eligible pupils and not just absorbed into the general school budget. But it rules out possibly the most important thing that a school could use the money for – to pay a bit more to hire a more effective maths or English teacher. One priority is to find a way to maintain the monitoring of the PP spend whilst opening up these possibilities.
Will the PP be continued into the next Parliament? Both Labour and Conservatives have pledged to ‘protect’ the school budget, and while that obviously does not imply a line-by-line protection, it would seem hard to square these pledges with the scrapping of the PP. While money as a whole does not seem to matter as much in this context as others, losing a substantial additional sum focussed specifically on disadvantaged pupils would feel like a step backwards.
Education Policy in the Election 1: Teachers and teaching
By: Simon Burgess
There is a paradox here. The key research finding is that teacher effectiveness is hugely important for pupil attainment – much more so than class size, IT in the classroom, or any of the other policies that politicians typically reach for. Perhaps unusually, this evidence has made its way into the policy debate fairly quickly and is now widely accepted. Teacher effectiveness is about pupil attainment: a highly effective teacher is one whose pupils make strong academic progress. Teachers do many things for their pupils but policy should surely be focussed first on attainment. In this country, our work
showed that putting effective teachers in front of a pupil instead of ineffective teachers for all subjects just for the two GCSE years wipes out half of the GCSE points gap between kids from disadvantaged families and the rest. So the prize for a great policy is huge.
You might think that this would mean that teachers are at the centre of the policy debate, with the parties and think tanks producing detailed discussion of the best policies to raise teacher effectiveness. With two main exceptions discussed below, there has been little new policy making about teacher effectiveness.
In fact, this relative neglect is probably justified. It is proving hard for researchers to progress from that initial, crucial, finding about teacher effectiveness. We researchers have not yet solved the questions of how to improve teacher effectiveness. It should be said that this is not through want of trying: this is a major focus of research effort here and in the US. The research agenda lying before myself and other researchers in this field includes: what do effective teachers do? Can this be learned? Or is it about selection? Can we measure effective teaching? What should the teacher “professional journey” be, and what contract forms support that? The difficulties are in obtaining robustly causal estimates, and of running large scale random control trials in schools. Hopefully we will have some of that evidence in time to inform policy soon.
The two areas of policy affecting teachers are the demand for only qualified teachers in schools; and the devolved introduction of performance pay for teachers.
Unqualified teachers? or continuously re-qualified teachers?
The Conservatives have allowed unqualified teachers, and UKIP support this. Labour say that they would require that all teachers hold or are working towards Qualified Teacher Status (QTS). To me, it seems unlikely that this is a first order issue for pupil attainment. While there is no specific evidence relating robust estimates of effectiveness with QTS status, in general the bulk of the international evidence shows that there is little relationship between the individual’s own academic career and her/his effectiveness as a teacher; nor any consistent gaps in effectiveness by route of entry into teaching.
So in itself it is probably not a big deal. However, it may be a politically astute way of bringing in, as a package, another item in the Labour manifesto. This is the pledge to require teachers to “keep their skills and knowledge up to date” throughout their careers “as a condition of remaining in the classroom”. This is potentially a very important proposal, albeit trailed previously, and if pursued vigorously could make a significant difference to average teacher effectiveness. The key questions will be about implementation, and while there is scope for this to be game-changing, there is also scope for it to simply provide more paperwork for no real gain.
Performance pay for teachers
Since September 2014 all state-funded schools in England, academies and non-academies, are required to have a performance pay system for teachers. Not “allowed to”, but “required to”. The international evidence on the likely effects of this is genuinely mixed. Those on both sides of the argument can point to high quality studies by leading researchers that find substantial positive effects, or no effects.
But in a sense the potentially more impactful element of the policy is that schools are left to determine the nature of the scheme themselves. Designing performance pay schemes is complex with many factors to decide, and many opportunities to make crazy choices. In fact some, maybe many, schools have adopted policy templates produced by others – their LAs, headteacher unions, and so on. But still, the scope for some disastrous outcomes is not negligible.
At CMPO we have investigated performance pay in the public sector for teachers, doctors, and bureaucrats in JobCentres, and in Customs and Excise (as was), also evidence reviews here.
The two common findings are: firstly, incentives work, sometimes powerfully; but secondly that that powerful effect can be mis-directed if the scheme is badly designed. Having 30,000 schools write their own performance pay schemes is certainly in line with a less prescriptive, more autonomous schools system; it is also playing with fire.
Gender, teacher assessment and stereotypes
By: Simon Burgess
The gender gap in attainment is a key fact of our times, with girls now out-performing boys pretty much throughout the education system. Nevertheless, there are currently significant gaps in jobs: women are still under-represented in science, technology, engineering and mathematics. How the gap in qualifications plays out into jobs and pay over the next twenty years or so is going to have significant consequences for the nature of work, the composition of the leading professions, family life, bringing up children and more.
But that’s for the future. For now, we are still trying to understand the implications of the gender gap in schools. Last week a new report from the OECD uses the PISA data to shed more light on the gender gap across a large group of countries. The TES highlights the conclusions drawn about teacher assessments and stereotyping:
“ … while teachers generally reward girls with higher marks in both mathematics and language-of-instruction courses, after accounting for their PISA performance in these subjects, girls’ performance advantage is wider in language-of-instruction than in mathematics. This suggests both that girls may enjoy better marks in all subjects because of their better classroom discipline and better self-regulation, but also that teachers hold stereotypical ideas about boys’ and girls’ academic strengths and weaknesses.” (OECD, p. 56)
These findings echo CMPO research by Ellen Greaves and I on teacher assessments and pupil ethnicity. While we focussed on ethnicity, we also included gender and social status in the analysis.
We used data from the National Pupil Database (NPD) to compare written tests and teacher assessments of the same characteristic, namely the pupil’s ability in Maths, English and Science. The tests were nationally set and remotely marked; the teacher assessment was provided by the pupil’s subject teacher.
We can make this comparison because the end of Keystage 2 at age 11 has both these forms of assessments. There is no presumption that one form of the assessment is the Truth and one is biased. They are independent but noisy measures of the same underlying characteristic – just how good is this pupil at maths? But a comparison of the two across a large sample is revealing. Since we used all the eleven year-olds in England, our sample is big enough. Overall, the most common outcome is that the two estimates of ability agree, there is no difference between teacher assessment and remotely marked test.
But there are systematic patterns in the differences that are very interesting. In terms of gender, our findings for England are similar to the OECD, although since we use NPD data from the mid 2000’s, girls’ progress has moved on. We show that girls are “over-assessed” in English and “under-assessed” in maths. That is to say: the gaps between the test and the teacher assessment are on average positive in maths and negative in English for girls.
In terms of social class, we found that pupils eligible for free school meals were “under-assessed” on all three subjects.
Another way of saying the same thing is that poor pupils systematically and significantly out-performed what their teachers thought they would achieve.
We show the results for different ethnic, gender and social divides in the graph below. It shows very starkly that groups doing well in a test at a national level tend to be over-assessed by teachers; and equivalently, groups doing badly nationally tend to be under-assessed.

None of this is to say that teachers are biased. Like everyone else all the time, they use stereotypes to help make decisions when their information is imperfect.
But there are consequences. It is important that we do not rely solely on teacher assessments and that we retain and use nationally set and remotely marked tests. Using teacher assessments rather than the test scores to define attainment would result in a much greater recorded gap between poor and non-poor pupils. Tests allow pupils to show what they can do independently of someone’s opinion of them, including that person being their teacher.
Do place-based policies achieve their objectives?
By: Helen Simpson
Place-based policies such as enterprise zones target specific geographic areas, rather than specific groups of people. Even so, their ultimate aim is often to create jobs and boost incomes of relatively disadvantaged residents. A new Federal Reserve Bank of San Francisco Economic Letter, by David Neumark and Helen Simpson, discusses the evidence on whether place-based policies meet their objectives. The evidence on enterprise zones is mixed, with some studies finding no effects on employment and others finding positive effects on job creation. There is also no clear cut evidence that enterprise zones reduce poverty, and some evidence that they lead to house price increases, suggesting that the end beneficiaries may well differ from those the policy originally set out to help.
While targeting specific areas to take advantage of “agglomeration benefits” (that is, the productivity boost stemming from increased density of firms and workers), or purely on equity grounds is justifiable, the intended effects of policies that target “place” rather than “people” can be undone by geographic mobility. Firms may simply re-locate into subsidised areas, calling into question the nationwide benefits of an area-based subsidy if jobs are simply being geographically reshuffled, and people may also move. This means that the ultimate beneficiaries of any new jobs may not be the original disadvantaged residents, and that homeowners and landlords may benefit from increased property values. Given this, place-based policies aimed at specific locations should be closely evaluated to fully understand who exactly it is that gains any benefits, and whether these come at a cost to other individuals or areas.
Will a decrease in stamp duty actually help first time buyers?
By: Mike Peacey
Yesterday George Osborne delivered his autumn statement. Perhaps the most significant reform is that of stamp duty land tax. Unsurprisingly this tax has been criticized by numerous interested parties for some time. The infamous feature of stamp duty was that the marginal tax rate exceeds 100% every time the price crosses one of the thresholds, because a single tax rate applies to the whole transaction. This tax has been labelled “Britain’s worst tax”, being distortionary and unfair. Reforms to stamp duty have been in the pipeline for years (my two pence worth), and this year Scotland announced its own overhaul of the tax.
George Osborne’s reform eliminates the most objectionable feature – now the threshold will only affect the proportion of the property above it. The other change is to the rates of tax. The results are that most property sales below £1.125m will now pay a lower tax (and very expensive houses will now pay a much larger amount).
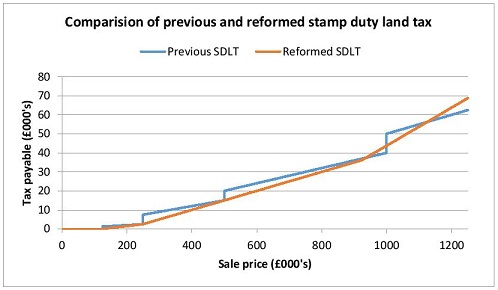
On the face of it this reform appears to make sense. The purpose of most taxes is to raise revenue and redistribute wealth. Stamp duty does raise significant revenue – having recently overtaken revenue raised by tobacco taxes. Although this reform is expected to reduce government revenue by around £800m (approximately 12.5%), it is claimed to also benefit 98% of homebuyers.
A first year economics textbook teaches us two important ideas about taxation: deadweight losses and tax incidence. The purpose of trade is to reassign property to the party who values it most. However, if the increase in value the buyer places on the property (above the seller) is less than the tax amount the sale won’t happen. When this happens the tax has resulted in dead weight loss. Tax incidence refers to the subtle difference between who is legally responsible for payment (in the case the buyer) and who in practice picks up the bill. The distinction arises because the buyer will take payment of the tax into account when deciding on her offer.
If 98% of homebuyers pay less tax does this imply they are necessarily better off? Not necessarily. Focusing on these individuals (think 6, not 7, figure house prices), there are reasons which suggest this tax reduction might make them worse off.
Current first time buyers are credit constrained: Many could afford the loan repayments on a more expensive property, but not the deposit. Since stamp duty cannot be added to a mortgage, the buyer must have enough for this tax payment in addition to their deposit. If the tax reduction gives buyers the opportunity to increase their deposit, banks might respond by permitting them to increase their leverage. This raises the possibility that a relatively small tax reduction might, via a multiplier effect, significantly increase house prices – making those buyers worse off.
Best and Kleven (2013) have shown that house prices respond to changes in stamp duty by bunching at new thresholds. Removing the cliff edge will smooth the price distribution – and permit an increase in average house prices. Moreover, since the majority of transactions involve some bargaining, we should consider the introduction of taxes in this framework. Chae (2002) showed us there are situations in which parties can actually benefit from a higher tax! My own research into the UK housing market backs this up: suggesting that the cliff edge property of stamp duty provides such a benefit to buyers.
First time buyers rejoicing in the belief they can now afford a house might be disappointed. If the most objectionable feature of the tax – the cliff edge property – has been keeping prices (across the whole market) down, perhaps homeowners not homebuyers should be rejoicing. Economics 101 teaches us that the legal and economic incidence of a tax is not the same. A tax reform intended to help first time buyers might paradoxically make them worse off, especially if it fuels house price inflation.
London, ethnicity and GCSEs: Response … and a question for you
By: Simon Burgess
One of the things to come out of the response to day before yesterday’s blog was a clear desire to hang on to the ‘London Effect’. This is the belief that the much higher GCSE scores in London than the rest of England are the result of some policy or practice in the capital’s schools.
As I show in the report and as Chris Cook demonstrated here and before, this can be done by focussing on a subset of GCSE exams and taking that as the outcome measure. This is currently the only way that that belief can be supported.
I will come back to this below.
But here is the main point: I think we are in danger of missing the big issue by focussing on a debate over vocational qualifications. In this rush to hang on to the effects of a slightly mysterious policy, we are just marching past a demonstrable achievement of London. Sustaining a large, successful and reasonably integrated multi-ethnic school system containing pupils from every country in the world and speaking over 300 languages is a great thing. The role of ethnic minorities in generating London’s premium shows that London is achieving this. How many of those are there? I don’t know enough about school systems around the world to say, but I’d guess it’s probably unique.
To my mind, this is a fact worth celebrating about the London education system.
Having dwelt on that thought, here are two points on vocational qualifications.
First, the comparison of London and the rest of England, with and without vocational qualifications (VQs), and across ethnic groups is quite complex. Here are some things that are not true and some that are true.
1. It is not the case that White British pupils make better progress than pupils from ethnic minorities if we exclude VQs. The performances on this measure line up very strongly with performances on the regular measure, as shown in Figure 1:

2. It is not the case that pupils from all ethnic minorities do more VQs than White British pupils. Some do, some don’t: see the final column of table 1. Bangladeshi, Black African, Chinese and Indian ethnicity do fewer VQs than White British pupils; Pakistani and Black Caribbean pupils do more.

3. But it is the case that pupils of each ethnicity did more VQs in schools outside London than inside. See the first two columns of Table 1 above. All these differences are statistically significant. You can also see that in Figure 2 below, which also shows that outside London pupils did slightly more entries overall, meaning less study time per subject.

4. And it is the case that if we do exclude VQs, pupils from each ethnic group score higher on this progress measure in schools in London than outside. See table 2 below.

So the key question is: why did schools in London enter their pupils for far fewer VQs? Was this a city-wide policy decision? Or more informal but still common across London?
This is the question to you.
There is more on equivalents etc in a useful blog by Dave Thomson of FFT. He finishes with the same question.
Second, is it legitimate to decide now, after the fact, that some qualifications count less or not at all in a measure of what schools do? Obviously some vocational qualifications were severely Wolf’ed but not all.
Chris Cook and I have swapped analogies on this:
Chris: It’s a 110m hurdles race and we let schools choose their own hurdles, and then only look at their times at the finish. But we know some chose lower hurdles.
Me: athletes running a 400m race to find a winner. After the race, someone says that actually the proper test of run ability is just the first 200m so we will declare the true winner as the person ahead after 200m.
I am sure there is some truth in both (Any one coming up with a shot put-based analogy wins a prize.)
Finally, a thought about why there is this desire to hang on to the London Effect. If the higher GCSE progress had been the result of a policy (about 8 GCSE grades or 9.8% of an SD more technically) then it would be one of the best large scale policies ever. One reason I guess why people want to believe in it is that we lack a portfolio of proven, large scale public policies to raise educational attainment. Reiterating my comment from the paper, there are no innate differences in ability between pupils from different ethnic groups, but higher aspirations and expectations and perhaps a strong social network encouraging success matter a great deal. How to encourage that in groups where it can be absent is currently unknown; that is where the research frontier is.
London schools: the central role of ethnicity
by: Simon Burgess
Urban areas are often associated with poor educational attainment. But London is different. Recent analysis suggests that the attainment and progress of pupils in London is the highest in the country. A leading education policy commentator argues that: “Perhaps the biggest question in education policy over the past few years is why the outcomes for London schools have been improving so much faster than in the rest of the country”. Some have argued that this is the result of policies and practices adopted by London schools. If so, identifying the key policies is a great prize, with the hope that they can be implemented more broadly. Another recent report emphasises more the importance of primary schools.
In this research I have set out the evidence that a big part, almost all in fact, of the answer lies in the ethnic composition of London’s pupils. More broadly, my interpretation of this leads to a focus on pupil aspiration, ambition and engagement. There is nothing inherently different in the educational performance of pupils from different ethnic backgrounds, but the children of relatively recent immigrants typically have greater hopes and expectations of education, and are, on average, more likely to be engaged with their school work. This is not by chance of course; a key part of the London effect is its attraction to migrants and those aspiring to a better life.
There are two key and indisputable facts that lie behind this: ethnic minority pupils make better progress through school than white British pupils do, and ethnic minority pupils make up a much higher fraction of pupils in London. London also has a lot more recent migrants into the country. We showed some time ago that ethnic minority pupils make better progress to GCSEs than white British pupils. Given that these pupils typically live in more disadvantaged neighbourhoods and come from poorer families, their advantages must be less material than books, museum visits and computers. It is argued that ethnic minority pupils have greater ambition, aspiration, and work harder in school.
Put simply, this is the story: London has more of these pupils and so has a higher average GCSE score than the rest of the country. In this research, I put these two facts together and show that this accounts for almost all of the London effect.
The best way to measure what a school, or a city-wide school system, adds to its pupils is to look at pupil progress. This is what I do here. I focus on progress through secondary school, partly because the attainment measure at the start of secondary school is better than that for primary, and partly because others are focussing on primary schools. Progress is simply and standardly defined as capped GCSE points score relative to Keystage 2 scores.
What do we see? First, there is a London premium in pupil progress of just over 8 GCSE grade points, where a grade point is the difference between an A and a B, or a D and an E, etc. (for international comparability this is 9.8% of a standard deviation (SD). This is a huge number: the difference between say getting 8 C’s rather than 8 D’s. Given this, it is unsurprising there has been speculation as to what lies behind it. There is also a very substantial gap in the fraction of pupils progressing to at least 5 A*-C grades, 2.5 percentage points more in London.
Second, ethnic composition matters a great deal. In fact, differences in composition account for all of the gap in the progress measure. If I assume that London had the same ethnic composition as the rest of England, then given the progress of each ethnic group in each place (London, not London), there would be no ‘London Effect’. This decomposition is discussed in the paper, but an easy way to see this is a simple regression. Estimate the ‘London effect’ over all the pupils in all state schools in England, first not taking account of ethnicity and then adding those controls in, and Figure 1 (in SD units) shows that the effect is wiped out.

If I analyse conditional progress – taking account of personal circumstances such as poverty, gender, month of birth etc. – a London premium of 11% of an SD is also entirely eliminated by controls for ethnicity; this is also robust to conditioning on neighbourhood disadvantage as well. The Figure also shows that there is no significant difference between the progress of white British pupils in London and in the rest of the country, nor between pupils of Asian ethnicity in London and outside.
Third, it may well be that this effect is not a pupil’s ethnicity per se, but a characteristic that is correlated with ethnicity for some ethnic groups – being the child of immigrants. There is no educational data with immigrant status, so we have to use imperfect approximations. One way is to look at language – whether the pupil speaks English at home, or whether the pupil has English as an additional language (“EAL”). I also try another approximation in the paper.
Figure 2 shows again the impact on the estimated London Effect of controlling for language:

Of course, there has been change over the last decade. In fact, repeating this analysis it is clear that the London progress premium has existed for the last decade and is statistically accounted for by ethnic composition in each year. Again, it is easy to see why: London has seen a relative decline in its fraction of low-scoring pupils and a corresponding increase in high-scoring pupils:

There are two important cases in which accounting for ethnicity reduces (halves) the London premium but does not entirely eliminate it. If we consider GCSE points excluding vocational qualifications, then there remains a small but significant London effect. This in turn arises because pupils in London were entered for significantly fewer of these ‘equivalent’ qualifications. The implications of this are unclear. It is certainly not appropriate to simply remove some subject scores from the total and claim that the remainder represents ‘true’ progress. Nevertheless, the fact that London schools systematically entered pupils for less of these qualifications may represent the outcome of a particular policy.
Second, a measure of very high exam performance also yields a small but significant London effect once ethnicity is included. While this may also be the result of policy, it is also plausible that it derives from the very high concentration of professional families in London and their high input into their children’s education (which is not captured by a socio-economic control variable that just measures eligibility for free school meals).
Many policy makers, school leaders and commentators enthuse about the major policy of the time, London Challenge, and view it as unambiguously improving schools in London. This unanimity carries weight, and no doubt London schools were improved in a number of ways. But so far at least, catching a reflection of this improvement in the attainment data is proving to be difficult.
It sounds somehow uninspiring and disappointing that the London attainment premium is largely “accounted for by demographic composition” rather than wholly caused by some innovative policy. I disagree. It can be seen as a story of aspiration and ambition. There is nothing inherently different about the ability of pupils from different ethnic backgrounds, but the children of immigrants typically have high aspirations and ambitions, and might place greater hopes in the education system.
London has a right to be pleased with itself in terms of the excellent GCSE performance of its pupils. These results help to explain the ‘London Effect’; they do not explain it away. My argument is that the London effect is a very positive thing, and much of the praise for this should be given to the pupils and parents of London for creating a successful multi-ethnic school system.
Visit the CMPO Website

